 Hyemin Jung
2022.09.22
Hyemin Jung
2022.09.22
[ICML 2022] 2편: Self-supervised learning
|
ICML 2022(International Conference on Machine Learning 2022)는 올해로 39회째를 맞은 대규모 국제 학회입니다. 논문 채택률 20%, 임팩트 팩터 6.99로 매년 약 7만 명 이상이 참가하며 AI 분야에서 가장 영향력 있는 인공지능 학회 중 하나로 손꼽히고 있습니다. LG AI연구원은 지난 7월 17일부터 23일까지 미국 메릴랜드 볼티모어와 온라인에서 하이브리드로 개최되었던 'ICML 2022'에 참관했습니다. LG AI연구원의 세 연구원이 학회에서 공유되었던 내용 중 유의미한 논문을 골라 소개합니다. |
Introduction
Unsupervised Learning 방식 중 하나인 Self-supervised learning은 라벨이 없는 dataset으로부터 의미 있는 data representation을 학습하는 방법입니다. Self-supervised learning은 크게 두 가지 방향으로 분류됩니다. 첫 번째는 ‘Self-prediction’으로 data sample에서 일부를 보고 다른 부분을 predict 함으로써 representation을 학습하는 방법입니다. 두 번째는 ‘Contrastive learning’입니다. 이는 비슷한 sample 들은 가깝게, 서로 다른 sample 들은 멀게 위치하는 embedding space를 학습하는 방법입니다. 많은 연구가 위의 두 가지 방향으로 진행되고 있고, 올해도 ICML 2022에서 Self-supervised learning 관련 논문들이 다수 발표되었습니다. 이번 글에서는 ICML 2022에서 발표된 Self-supervised learning 논문 중 인상 깊었던 논문 두 편에 대해서 설명하겠습니다.
Adversarial Masking for Self-Supervised Learning[1]
Motivation
Masked image modeling은 representation을 학습하는 한 방법으로 이미지 데이터의 일부분을 Masking하고 이를 복원하는 방법입니다. 이는 BERT와 같은 Language modeling의 방법에서 착안한 것입니다. 학습 대상이 언어일 경우에는 Figure 1처럼 masking 되는 것이 하나의 semantic 의미를 가지는 word이기 때문에 모델이 masking 된 word를 복원할 때 주변의 context 정보를 이용합니다.

Figure 1
그러나 학습 대상이 이미지의 경우 Figure 2처럼 일부 픽셀을 random 하게 masking하고 복원합니다.

Figure 2
이 경우, 주변의 context 정보를 사용하는 것이 아니라 local correlation을 이용해서 쉽게 복원합니다. 그러나 이렇게 하면 이미지의 semantic 정보가 담긴 representation이 제대로 학습되지 않는 문제가 있습니다. 따라서 이미지의 semantic 정보가 잘 담긴 representation을 학습하기 위해서는 어떤 부분이 masking 되는지가 중요합니다.
이 논문에서는 이미지의 representation 학습을 위해 어떤 부분을 masking 하면 좋은지를 학습하고 이를 이용하는 Self-supervised learning framework인 ‘ADIOS’입니다. 제안한 방법으로 masking 한 결과는 아래와 같으며, 지금부터 구체적인 방법에 관해서 설명하겠습니다.

Figure 3
Method
ADIOS의 전체 구조는 Figure 4와 같이 Inference model과 Occlusion model로 구성됩니다.
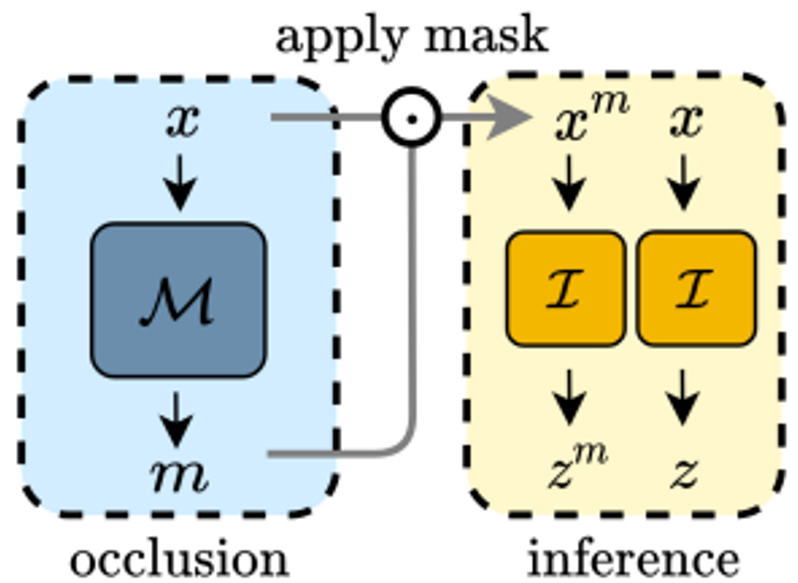
Figure 4. ADIOS Architecture
Figure 4에서 왼쪽에 있는 Occlusion model (M)은 원본 image sized mask를 generate하는 모델입니다. 오른쪽의 Inference model (I) 은 occluded image와 원본 image를 입력 받아서 둘의 representation을 각각 계산하는 모델입니다. 참고로 Inference model은 encoder 부분만 사용했습니다. 최근 연구에서 Generative model을 사용해서 pixel level reconstruction 하는 부분이 오히려 modelling capacity만 낭비하고, subpar performance를 보인다는 연구 결과가 나왔기 때문입니다.
두 모델은 아래와 같이 adversarially 학습됩니다.
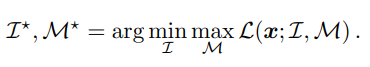
위 식으로 모델을 학습시키면 Occlusion model은 masked version과 원본의 representations 사이의 distance가 maximize 하도록 하고, Inference model은 둘의 distance를 minimize 하도록 합니다. 이제 각 모델에 대해서 자세히 살펴보겠습니다.
<Inference model>
우리가 연구를 통해 구성하고자 하는 encoder의 역할은 masked image가 들어오면 missing 된 부분을 observed context 정보를 이용해서 복원하고, 입력된 image의 representation을 계산하는 것입니다. 즉 encoder에 masked image를 입력시켰을 때와 원본 image를 입력시켰을 때 나오는 representation이 모두 동일해야 합니다. 이를 위해서 아래와 같은 목적식을 제안합니다. (D는 distance를 계산하는 metric입니다)
위의 식으로 학습하게 되면 encoder가 두 representation 사이의 distance를 minimize 하기 위해서 masked image의 masking 부분을 reasoning 합니다.
Inference model 구조는 기존에 나온 Self-supervised model 중 augmented image views를 사용하는 모델(SimCLR, BYOL, SimSiam)을 사용하면 됩니다. 세 모델은 모두 두 개의 view를 사용하는데, 이 모델들에 ADIOS를 적용하는 공통적인 방법은 한 개의 view에 Occlusion model에서 나온 mask를 적용하고 이를 입력하는 것입니다.
SimCLR에 제안하는 ADIOS를 적용한 구조와 목적 식은 아래와 같습니다.
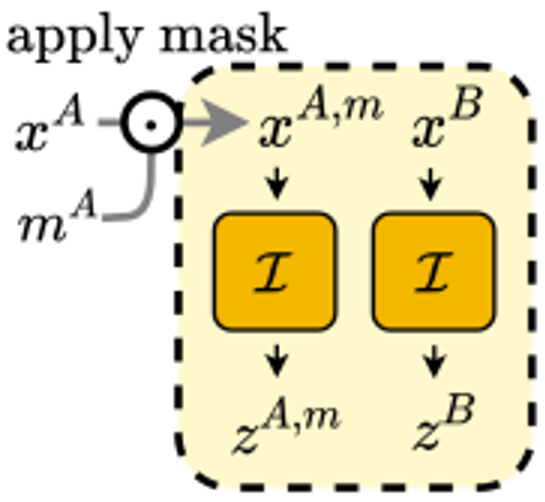
Figure 5
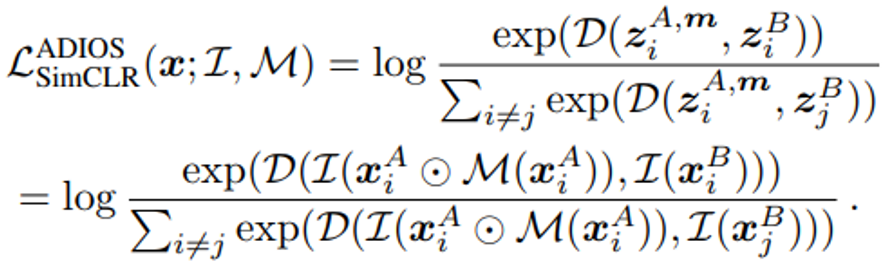
SimSiam에 제안하는 ADIOS를 적용한 구조와 목적 식은 아래와 같습니다.
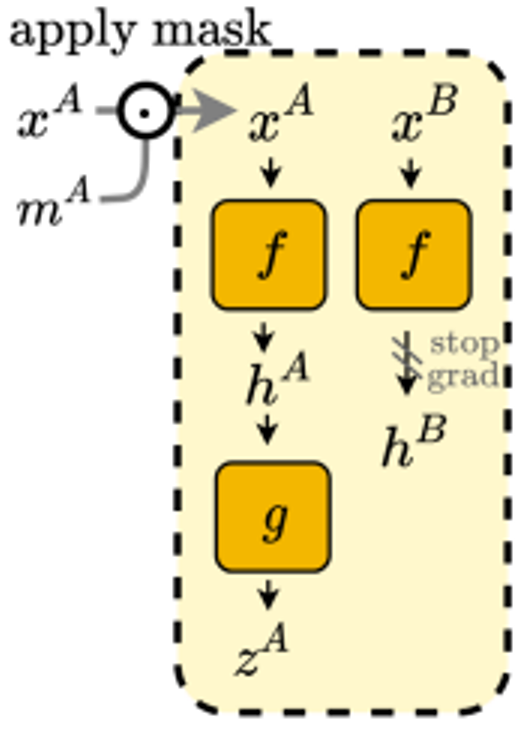
Figure 6
BYOL에 제안하는 ADIOS를 적용한 구조와 목적 식은 아래와 같습니다.
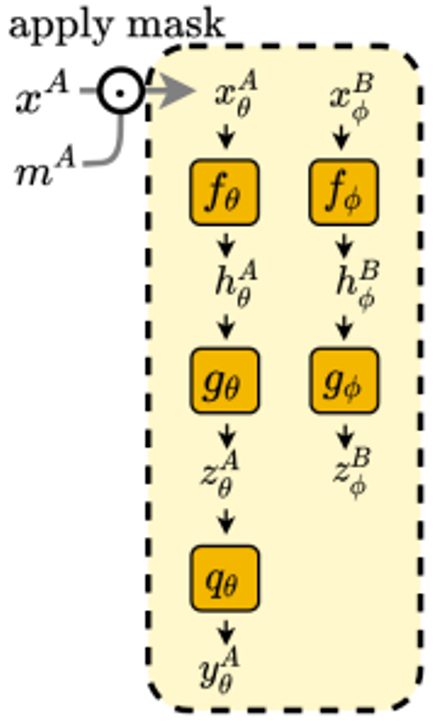
Figure 7
<Occlusion model>
Occlusion model은 mask를 한 개 또는 여러 개를 생성할 수 있습니다. 각 mask가 이미지의 다른 component 들을 masking 하면 Inference model이 masked 된 부분을 reasoning 하면서 relations를 학습합니다. 이때 Occlusion model의 구조는 U-Net 구조를 사용해 U-Net에서 나온 원본 크기의 feature map에 1*1 convolution을 N개 사용해서 최종적으로 N개의 mask가 나오도록 했습니다. 그리고 Mask의 값을 0과 1로 binarising하거나, real-valued masks를 바로 사용할 수 있다고 했습니다.
<전체 구조>
N개의 mask를 생성해서 사용하는 모델의 구조는 아래와 같습니다.
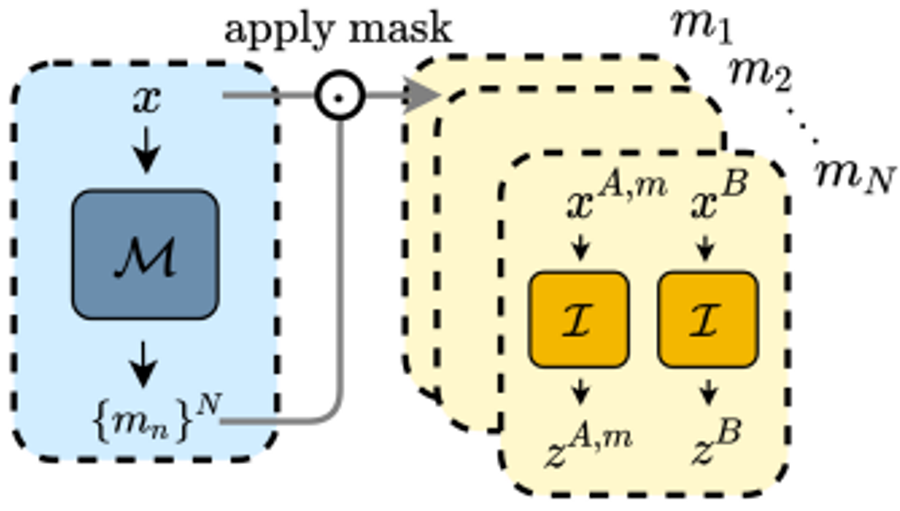
Figure 8. ADIOS, N>1
전체 Loss 식은 아래와 같이 N개의 mask를 사용한 loss를 평균 낸 것입니다.
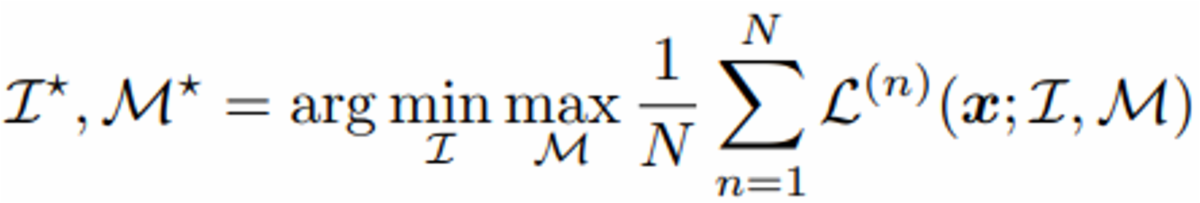
그러나 위의 목적 식으로 학습하게 되면 Occlusion model에서 나오는 mask 값들이 모두 0이거나, 1이 될 수 있습니다. 논문에서는 이를 방지하기 위해서 추가로 아래의 Sparsity penalty를 사용할 것을 제안합니다.
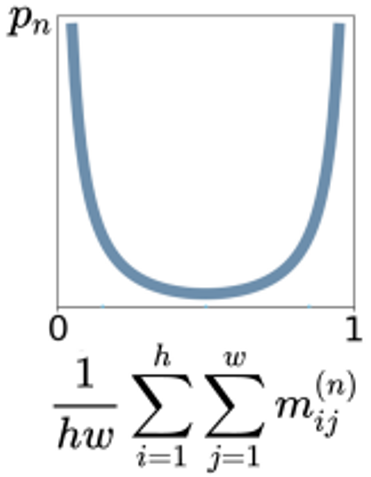
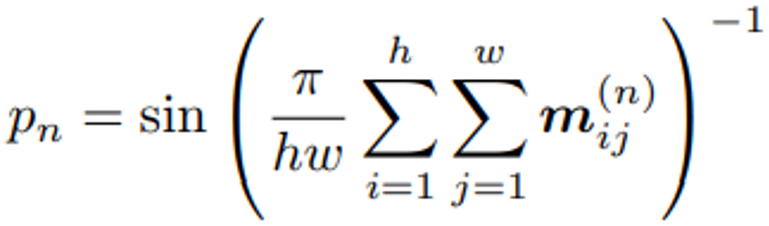
위의 Sparsity penalty를 추가로 minimize 함으로써 mask 값이 모두 0 또는 1이 되는 것을 방지합니다.
위의 penalty를 적용한 최종 loss 식은 아래와 같습니다.
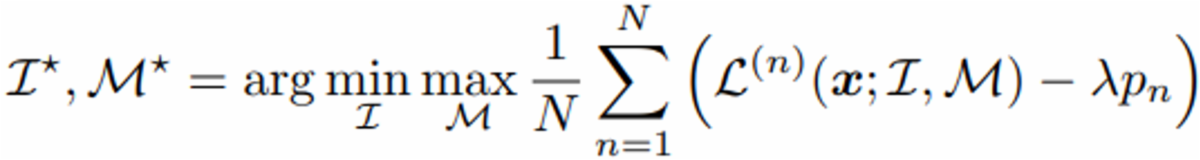
위의 식을 계산하기 위해서는 N 번의 encoder forward pass가 필요한데, 이는 computationally expensive합니다. 따라서 논문에서는 추가적으로 lightweight version을 아래와 같이 제안합니다.
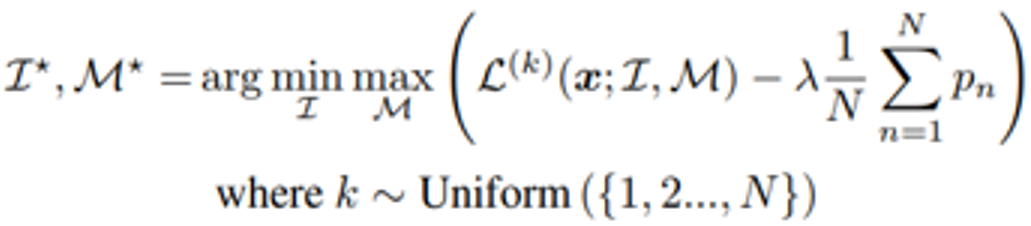
Lightweight version은 N개의 generated masks 중에서 한 개를 randomly sample 해서 input image에 적용하는 것입니다. 지금부터는 논문에서 제안한 방법으로 실험한 결과를 설명하겠습니다.
Experiment
제안한 방법을 적용한 self-supervised learning으로 representation을 학습하고 이를 이용한 classification, transfer learning의 결과는 Table 1과 같습니다.
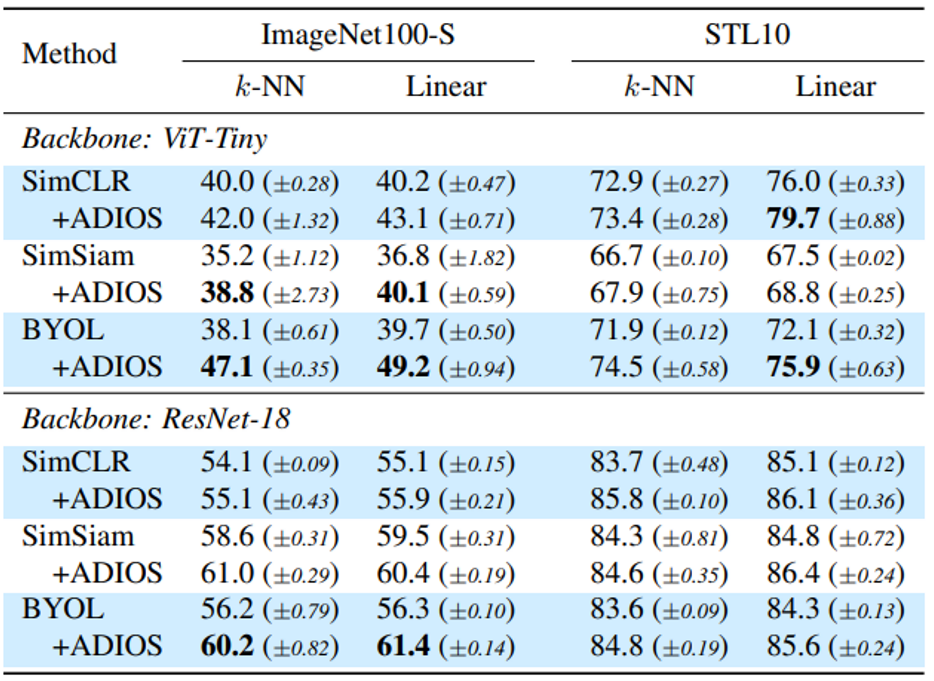
Table 1
Classification task에서 ADIOS를 적용했을 때 모두 성능이 향상됐습니다.
ImageNet100-S로 self-supervised learning 한 다음, 네 개의 다른 datasets에 대해서 transfer learning을 수행했는데 모두 성능이 향상되었고 그 결과는 Table 2와 같습니다.
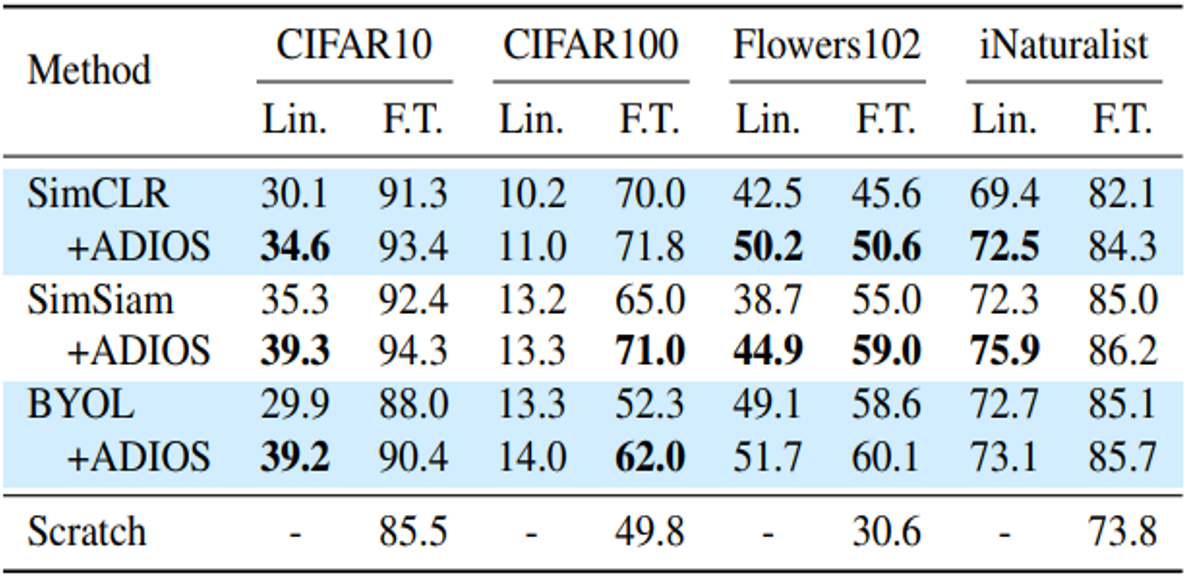
Table 2

Figure 9
Self-Supervised Representation Learning via Latent Graph Prediction[2]
Motivation
Graph에 Self-supervised learning 방식을 적용한 방법은 크게 Contrastive methods와 Predictive method 두 개로 분류됩니다. Predictive method는 masked input graph에서 masking 된 부분을 reconstruction 하는 것입니다. 예를 들어서 node reconstruction, connectivity reconstruction 등이 있습니다. 이 논문은 Predictive method 기반의 Self-supervised learning을 제안합니다.
Method
문제의 목표는 encoder에 graph 정보인 adjacency matrix, node features가 입력되면, 의미 있는 node-level, graph-level representation을 계산하기 위한 pre-text learning task를 제안하는 것입니다.
논문에서 제안하는 pre-text learning task를 이해하기 위해서, 먼저 latent data 개념에 관해서 설명하겠습니다.
주어진 observed data instance x에 대응하는 latent data 가 있습니다. Observed data instance x의 semantic 정보는 latent data에 의해서 정해집니다. 보통 observed data는 noisy version이고, latent data는 clean version입니다. 이 개념을 graph data에 적용하면, observed graph data G=(A,X)는 latent graph =(A,F)로부터 generated 된 noisy 한 graph입니다. 둘은 same node set, edge set을 가지고, node feature matrices X와 F는 동일한 dimensionality를 가집니다. Latent data가 observed data의 semantic meaning을 결정하기 때문에 latent data를 supervision signal로 사용하는 pre-text learning task를 정의했습니다. Latent data를 prediction 하면서 의미 있는 node level, graph level의 representation을 학습할 수 있습니다.
이를 적용한 Latent graph prediction task의 목적 식은 아래와 같습니다.
그러나 observed graph data G=(A,X)는 주어지나, latent graph =(A,F) 정보는 알 수 없어서, 위의 목적 식을 바로 계산할 수는 없습니다. 이 문제를 해결하기 위해서 논문에서는 위의 목적 식을 대체하는 upper bound를 제안합니다.
<Node-level Representation>
각 node의 representation을 계산하기 위한 upper bound는 아래와 같습니다.

Latent graph의 node feature F를 prediction 하는 목적 식의 upper bound는 두 개의 term으로 구성되어 있습니다. 첫 번째 term은 reconstruction term으로, encoder에서 나온 node의 representation 정보가 informative 하도록 하는 term이고, 두 번째 term은 invariance regularization term으로, 해당 node의 feature이 주어지지 않아도, 그 node의 input feature를 잘 reconstruct 하게 하는 term입니다.
위의 목적 식을 계산하는 전체 과정은 Figure 10과 같습니다.
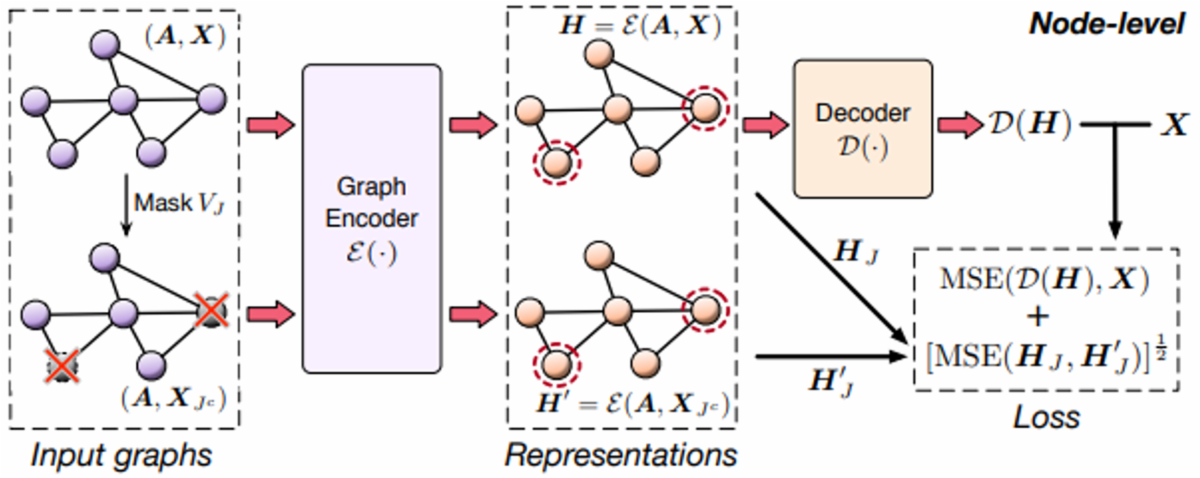
Figure 10
G=(A,X)가 주어지면, 여기에 일부 sub-set node를 masking 한 graph G'를 만듭니다. 두 그래프를 encoder에 각각 입력시켜서 node 들의 embedding을 계산합니다. (H와, H' 계산) H를 fully connected layer로 구성된 decoder에 입력시켜서 전체 node의 feature를 복원시키고, 이 값을 이용해서 reconstruction term을 계산합니다. Invariance regularization term을 계산하기 위해서, H와 H' 중에서 masked node 부분의 feature 들의 차이를 계산합니다.
<Graph-level Representation>
Graph의 representation을 계산하기 위한 upper bound는 아래와 같습니다.

위의 목적 식을 계산하는 전체 과정은 Figure 11과 같습니다.
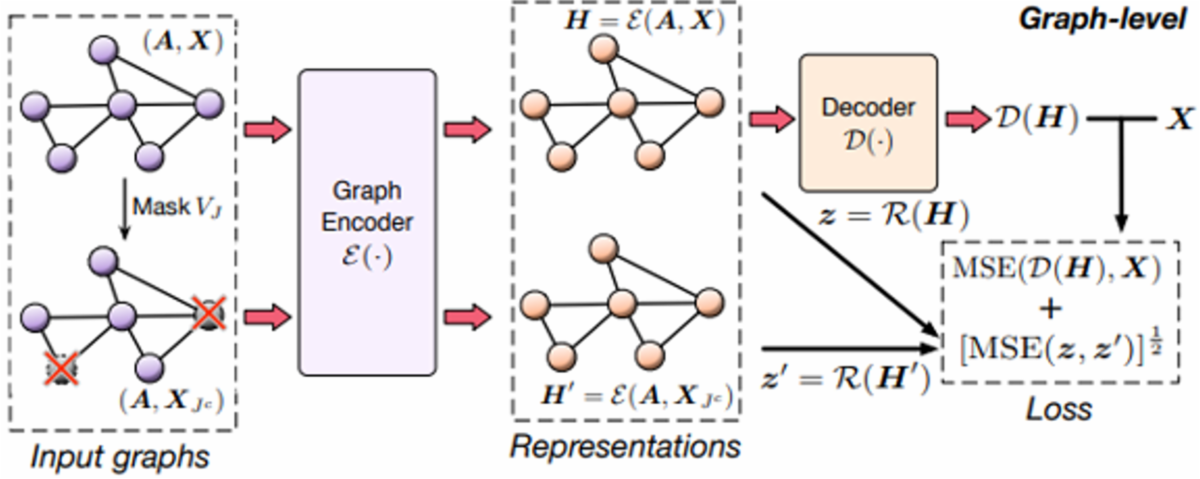
Figure 11
Invariance regularization term을 계산하는 부분만 node-level representation을 계산하는 방법과 다릅니다. H, H'를 Read out function에 통과시켜서 나온 그래프의 embedding z, z’를 계산하고 구한 각 그래프의 representation 들의 차이를 계산합니다.
Experiment
제안한 방법을 적용해서 node-level representation과 graph-level representation을 계산하는 encoder를 학습하고 실험을 진행했습니다. 학습된 encoder에서 나온 node-level representation을 고정하고 Linear classifier 학습 후 evaluation 한 결과는 Table 3과 같습니다.
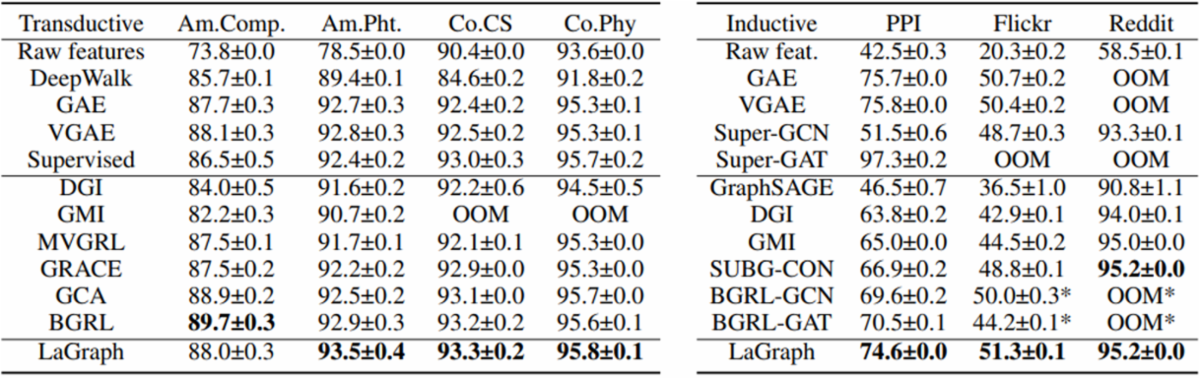
Table 3
학습된 encoder에서 나온 graph-level representation을 고정하고 Linear classifier 학습 후 evaluation 한 결과는 Table 4와 같습니다.
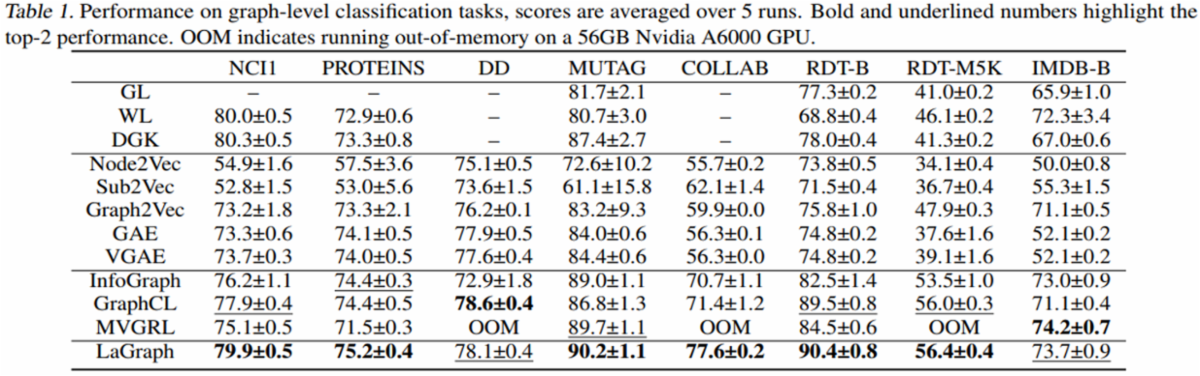
Table 4
두 실험 결과 모두 제안한 방식의 성능이 기존의 graph에 Self-supervised learning을 적용한 방법보다 좋은 것을 확인할 수 있습니다.
Conclusion
두 논문의 내용을 요약하면 “Adversarial Masking for Self-Supervised Learning”은 image data에서 좋은 representation 학습하는 데 도움이 되는 mask를 생성하는 방법을 제안했고, “Self-Supervised Representation Learning via Latent Graph Prediction”에서는 graph domain에서 predictive self-supervised learning 방법을 제안하여 SOTA 기록을 세웠습니다.
위의 논문 두 편 외에도 메타러닝 컨셉을 적용한 방법, 이미지, 언어 등 여러 domain에 적용 가능한 방법 등 흥미로운 Self-supervised learning 논문들이 이번 2022 ICML 학회에 발표되었습니다.
- 참고
- [1] Yuge Shi, N. Siddharth, Philip H.S. Torr, Adam R. Kosiorek “Adversarial Masking for Self-Supervised Learning” (2022) [2] Yaochen Xie, Zhao Xu, Shuiwang Ji “Self-Supervised Representation Learning via Latent Graph Prediction” (2022)